Encodage des données
Introduction et notation
Pour utiliser un algorithme quantique, les données classiques doivent d'une façon ou d'une autre être introduites dans un circuit quantique. On parle généralement d'encodage des données, mais aussi de chargement des données. Rappelle-toi des leçons précédentes la notion de mapping de caractéristiques (feature mapping), c'est-à-dire un mapping des caractéristiques des données d'un espace vers un autre. Le simple transfert de données classiques vers un ordinateur quantique est une sorte de mapping, et pourrait être appelé un feature mapping. En pratique, les feature mappings intégrés dans Qiskit (comme z_feature_map et zz_feature_map) incluent généralement des couches de rotation et des couches d'intrication qui étendent l'état à de nombreuses dimensions dans l'espace de Hilbert. Ce processus d'encodage est une partie critique des algorithmes d'apprentissage automatique quantique et affecte directement leurs capacités computationnelles.
Certaines des techniques d'encodage présentées ci-dessous peuvent être simulées de façon efficace sur un ordinateur classique ; c'est particulièrement facile à voir dans les méthodes d'encodage qui produisent des états produits (c'est-à-dire qu'elles n'intriquent pas les qubits). Et rappelle-toi que l'utilité quantique réside très probablement là où la complexité quantique du jeu de données est bien adaptée à la méthode d'encodage. Il est donc très probable que tu finisses par écrire tes propres circuits d'encodage. Ici, nous présentons une grande variété de stratégies d'encodage possibles, simplement pour que tu puisses les comparer et les mettre en contraste, et voir ce qui est possible. On peut formuler quelques affirmations très générales sur l'utilité des techniques d'encodage. Par exemple, efficient_su2 (voir ci-dessous) avec un schéma d'intrication complet est bien plus susceptible de capturer les caractéristiques quantiques des données que les méthodes qui produisent des états produits (comme z_feature_map). Mais cela ne signifie pas qu'efficient_su2 est suffisant, ou suffisamment bien adapté à ton jeu de données, pour produire une accélération quantique. Cela nécessite une réflexion approfondie sur la structure des données à modéliser ou à classer. Il y a aussi un équilibre à trouver avec la profondeur des circuits, car de nombreux feature maps qui intriquent entièrement les qubits dans un circuit produisent des circuits très profonds, trop profonds pour obtenir des résultats utilisables sur les ordinateurs quantiques actuels.
Notation
Un jeu de données est un ensemble de vecteurs de données : , où chaque vecteur est de dimension , c'est-à-dire . Cela pourrait être étendu à des caractéristiques de données complexes. Dans cette leçon, nous pourrons utiliser occasionnellement ces notations pour l'ensemble complet et ses éléments spécifiques comme . Mais nous nous référerons principalement au chargement d'un seul vecteur de notre jeu de données à la fois, et nous nous référerons souvent simplement à un seul vecteur de caractéristiques comme .
De plus, il est courant d'utiliser le symbole pour désigner le feature mapping du vecteur de données . En informatique quantique spécifiquement, il est courant de désigner les mappings quantiques par une notation qui renforce la nature unitaire de ces opérations. On pourrait correctement utiliser le même symbole pour les deux ; ce sont tous les deux des feature mappings. Tout au long de ce cours, nous utilisons :
- quand nous discutons des feature mappings en apprentissage automatique, de façon générale, et
- quand nous discutons des implémentations en circuits des feature mappings.
Normalisation et perte d'information
En apprentissage automatique classique, les caractéristiques des données d'entraînement sont souvent « normalisées » ou redimensionnées, ce qui améliore souvent les performances du modèle. Une façon courante de le faire est d'utiliser la normalisation min-max ou la standardisation. Dans la normalisation min-max, les colonnes de caractéristiques de la matrice de données (disons, la caractéristique ) sont normalisées :
où min et max désignent le minimum et le maximum de la caractéristique sur les vecteurs de données du jeu de données . Toutes les valeurs de caractéristiques tombent alors dans l'intervalle unité : pour tout , .
La normalisation est aussi un concept fondamental en mécanique quantique et en informatique quantique, mais elle est légèrement différente de la normalisation min-max. La normalisation en mécanique quantique exige que la longueur (dans le contexte de l'informatique quantique, la 2-norme) d'un vecteur d'état soit égale à l'unité : , garantissant que les probabilités de mesure somment à 1. L'état est normalisé en divisant par la 2-norme ; c'est-à-dire en redimensionnant
En informatique quantique et en mécanique quantique, il ne s'agit pas d'une normalisation imposée par les gens sur les données, mais d'une propriété fondamentale des états quantiques. Selon ton schéma d'encodage, cette contrainte peut affecter la façon dont tes données sont redimensionnées. Par exemple, dans l'encodage en amplitude (voir ci-dessous), le vecteur de données est normalisé comme l'exige la mécanique quantique, et cela affecte le redimensionnement des données encodées. Dans l'encodage en phase, il est recommandé de redimensionner les valeurs des caractéristiques comme afin d'éviter toute perte d'information due à l'effet modulo- de l'encodage vers un angle de phase de qubit[1,2].
Méthodes d'encodage
Dans les prochaines sections, nous nous référerons à un petit exemple de jeu de données classique composé de vecteurs de données, chacun avec caractéristiques :
Dans la notation introduite ci-dessus, on pourrait dire que la caractéristique du vecteur de données de notre ensemble est par exemple.
Encodage en base
L'encodage en base encode une chaîne de bits classique dans un état de base computationnel d'un système à qubits. Prenons par exemple Cela peut être représenté comme une chaîne de bits , et par un système à qubits comme l'état quantique . Plus généralement, pour une chaîne de bits : , l'état à qubits correspondant est avec pour . Note que cela concerne une seule caractéristique.
L'encodage en base en informatique quantique représente chaque bit classique comme un qubit séparé, mappant la représentation binaire des données directement sur des états quantiques dans la base computationnelle. Lorsque plusieurs caractéristiques doivent être encodées, chaque caractéristique est d'abord convertie en sa forme binaire, puis assignée à un groupe distinct de qubits — un groupe par caractéristique — où chaque qubit reflète un bit dans la représentation binaire de cette caractéristique.
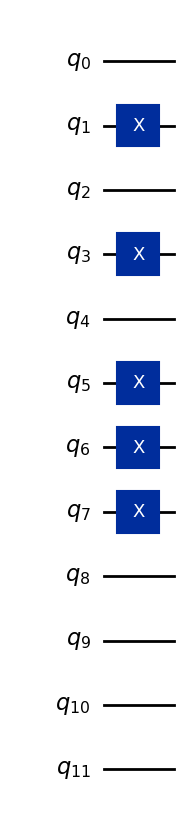
À titre d'exemple, encodons le vecteur (5, 7, 0).
Supposons que toutes les caractéristiques sont stockées sur quatre bits (plus que nécessaire, mais suffisant pour représenter tout entier à un chiffre en base 10) :
5 → binaire 0101
7 → binaire 0111
0 → binaire 0000
Ces chaînes de bits sont assignées à trois ensembles de quatre qubits, de sorte que l'état de base global à 12 qubits est :
Ici, les quatre premiers qubits représentent la première caractéristique, les quatre qubits suivants la deuxième caractéristique, et les quatre derniers qubits la troisième caractéristique. Le code ci-dessous convertit le vecteur de données (5,7,0) en un état quantique, et est généralisé pour le faire pour d'autres caractéristiques à un seul chiffre.
# Added by doQumentation — required packages for this notebook
!pip install -q matplotlib numpy qiskit
from qiskit import QuantumCircuit
# Data point to encode
x = 5 # binary: 0101
y = 7 # binary: 0111
z = 0 # binary: 0000
# Convert each to 4-bit binary list
x_bits = [int(b) for b in format(x, "04b")] # [0,1,0,1]
y_bits = [int(b) for b in format(y, "04b")] # [0,1,1,1]
z_bits = [int(b) for b in format(z, "04b")] # [0,0,0,0]
# Combine all bits
all_bits = x_bits + y_bits + z_bits # [0,1,0,1,0,1,1,1,0,0,0,0]
# Initialize a 12-qubit quantum circuit
qc = QuantumCircuit(12)
# Apply x-gates where the bit is 1
for idx, bit in enumerate(all_bits):
if bit == 1:
qc.x(idx)
qc.draw("mpl")
Vérifie ta compréhension
Lis la question ci-dessous, réfléchis à ta réponse, puis clique sur le triangle pour révéler la solution.
Écris du code pour encoder le premier vecteur de notre exemple de jeu de données :
en utilisant l'encodage en base.
Réponse :
import math
from qiskit import QuantumCircuit
# Data point to encode
x = 4 # binary: 0100
y = 8 # binary: 1000
z = 5 # binary: 0101
# Convert each to 4-bit binary list
x_bits = [int(b) for b in format(x, '04b')] # [0,1,0,0]
y_bits = [int(b) for b in format(y, '04b')] # [1,0,0,0]
z_bits = [int(b) for b in format(z, '04b')] # [0,1,0,1]
# Combine all bits
all_bits = x_bits + y_bits + z_bits # [0,1,0,0,1,0,0,0,0,1,0,1]
# Initialize a 12-qubit quantum circuit
qc = QuantumCircuit(12)
# Apply x-gates where the bit is 1
for idx, bit in enumerate(all_bits):
if bit == 1:
qc.x(idx)
qc.draw('mpl')
Encodage en amplitude
L'encodage en amplitude encode les données dans les amplitudes d'un état quantique. Il représente un vecteur de données classique normalisé de dimension , , comme les amplitudes d'un état quantique à qubits, :
où est la même dimension des vecteurs de données qu'auparavant, est le élément de et est le état de base computationnel. Ici, est une constante de normalisation à déterminer à partir des données encodées. C'est la condition de normalisation imposée par la mécanique quantique :
En général, il s'agit d'une condition différente de la normalisation min/max utilisée pour chaque caractéristique sur l'ensemble des vecteurs de données. La façon dont cela est géré dépendra de ton problème. Mais il n'y a pas moyen de contourner la condition de normalisation de la mécanique quantique ci-dessus.
Dans l'encodage en amplitude, chaque caractéristique d'un vecteur de données est stockée comme une amplitude d'un état quantique différent. Comme un système de qubits fournit amplitudes, l'encodage en amplitude de caractéristiques nécessite qubits.
À titre d'exemple, encodons le premier vecteur de notre exemple de jeu de données , en utilisant l'encodage en amplitude. En normalisant le vecteur résultant, on obtient :
et l'état quantique à 2 qubits résultant serait :
Dans l'exemple ci-dessus, le nombre de caractéristiques dans le vecteur n'est pas une puissance de 2. Lorsque n'est pas une puissance de 2, on choisit simplement une valeur pour le nombre de qubits telle que et on complète le vecteur d'amplitudes avec des constantes non informatives (ici, un zéro).
Comme pour l'encodage en base, une fois qu'on a calculé quel état encodera notre jeu de données, dans Qiskit on peut utiliser la fonction initialize pour le préparer :
import math
desired_state = [
1 / math.sqrt(105) * 4,
1 / math.sqrt(105) * 8,
1 / math.sqrt(105) * 5,
1 / math.sqrt(105) * 0,
]
qc = QuantumCircuit(2)
qc.initialize(desired_state, [0, 1])
qc.decompose(reps=5).draw(output="mpl")

Un avantage de l'encodage en amplitude est la nécessité mentionnée ci-dessus de seulement qubits pour encoder. Cependant, les algorithmes ultérieurs doivent opérer sur les amplitudes d'un état quantique, et les méthodes pour préparer et mesurer les états quantiques ont tendance à ne pas être efficaces.
Vérifie ta compréhension
Lis les questions ci-dessous, réfléchis à tes réponses, puis clique sur les triangles pour révéler les solutions.
Écris l'état normalisé pour encoder le vecteur suivant (composé de deux vecteurs de notre exemple de jeu de données) :
en utilisant l'encodage en amplitude.
Réponse :
Pour encoder 6 nombres, nous aurons besoin d'au moins 6 états disponibles sur les amplitudes desquels nous pouvons encoder. Cela nécessitera 3 qubits. En utilisant un facteur de normalisation inconnu , on peut écrire cela comme :
Note que
Donc finalement,
Pour le même vecteur de données écris du code pour créer un circuit qui charge ces caractéristiques de données en utilisant l'encodage en amplitude.
Réponse :
desired_state = [
9 / math.sqrt(270),
8 / math.sqrt(270),
6 / math.sqrt(270),
2 / math.sqrt(270),
9 / math.sqrt(270),
2 / math.sqrt(270),
0,
0,
]
print(desired_state)
qc = QuantumCircuit(3)
qc.initialize(desired_state, [0, 1, 2])
qc.decompose(reps=8).draw(output="mpl")
[0.5477225575051662, 0.48686449556014766, 0.36514837167011077, 0.12171612389003691, 0.5477225575051662, 0.12171612389003691, 0, 0]

Tu pourrais avoir besoin de traiter de très grands vecteurs de données. Considère le vecteur
Écris du code pour automatiser la normalisation et générer un circuit quantique pour l'encodage en amplitude.
Réponse :
Il y a de nombreuses réponses possibles. Voici du code qui affiche quelques étapes intermédiaires :
import numpy as np
from math import sqrt
init_list = [4, 8, 5, 9, 8, 6, 2, 9, 2, 5, 7, 0, 3, 7, 5]
qubits = round(np.log(len(init_list)) / np.log(2) + 0.4999999999)
need_length = 2**qubits
pad = need_length - len(init_list)
for i in range(0, pad):
init_list.append(0)
init_array = np.array(init_list) # Unnormalized data vector
length = sqrt(
sum(init_array[i] ** 2 for i in range(0, len(init_array)))
) # Vector length
norm_array = init_array / length # Normalized array
print("Normalized array:")
print(norm_array)
print()
qubit_numbers = []
for i in range(0, qubits):
qubit_numbers.append(i)
print(qubit_numbers)
qc = QuantumCircuit(qubits)
qc.initialize(norm_array, qubit_numbers)
qc.decompose(reps=7).draw(output="mpl")
Normalized array: [0.17342199 0.34684399 0.21677749 0.39019949 0.34684399 0.26013299 0.086711 0.39019949 0.086711 0.21677749 0.30348849 0. 0.1300665 0.30348849 0.21677749 0. ]
[0, 1, 2, 3]
Vois-tu des avantages à l'encodage en amplitude par rapport à l'encodage en base ? Si oui, explique.
Réponse :
Il peut y avoir plusieurs réponses. Une réponse est que, étant donné l'ordre fixe des états de base, cet encodage en amplitude préserve l'ordre des nombres encodés. Il sera souvent aussi encodé de façon plus dense.
Un avantage de l'encodage en amplitude est qu'il faut seulement qubits pour un vecteur de données à dimensions ( caractéristiques) . Cependant, l'encodage en amplitude est généralement une procédure inefficace qui nécessite une préparation d'état arbitraire, qui est exponentielle dans le nombre de portes CNOT. Autrement dit, la préparation d'état a une complexité de calcul polynomiale de en nombre de dimensions, où , et est le nombre de qubits. L'encodage en amplitude « fournit une économie exponentielle en espace au prix d'une augmentation exponentielle en temps »[3] ; cependant, des augmentations de temps de calcul à sont réalisables dans certains cas[4]. Pour une accélération quantique de bout en bout, la complexité du temps de calcul du chargement des données doit être prise en compte.
Encodage en angle
L'encodage en angle est intéressant dans de nombreux modèles QML utilisant des feature maps de Pauli comme les machines à vecteurs de support quantiques (QSVM) et les circuits quantiques variationnels (VQC), entre autres. L'encodage en angle est étroitement lié à l'encodage en phase et à l'encodage en angle dense qui sont présentés ci-dessous. Ici, nous utiliserons « encodage en angle » pour désigner une rotation en , c'est-à-dire une rotation hors de l'axe accomplie par exemple par une porte ou une porte [1,3]. En réalité, on peut encoder des données dans n'importe quelle rotation ou combinaison de rotations. Mais est courant dans la littérature, donc nous l'accentuons ici.
Lorsqu'elle est appliquée à un seul qubit, l'encodage en angle imprime une rotation autour de l'axe Y proportionnelle à la valeur des données. Considère l'encodage d'une seule caractéristique () du vecteur de données d'un jeu de données, :
Alternativement, l'encodage en angle peut être réalisé avec des portes , bien que l'état encodé ait une phase relative complexe par rapport à .
L'encodage en angle diffère des deux méthodes précédemment discutées de plusieurs façons. Dans l'encodage en angle :
- Chaque valeur de caractéristique est mappée à un qubit correspondant, , laissant les qubits dans un état produit.
- Une seule valeur numérique est encodée à la fois, plutôt qu'un ensemble entier de caractéristiques d'un point de données.
- qubits sont nécessaires pour caractéristiques de données, où . Souvent l'égalité tient ici. On verra comment est possible dans les prochaines sections.
- Le circuit quantique résultant a une profondeur constante (typiquement la profondeur est 1 avant la transpilation).
Le circuit quantique à profondeur constante le rend particulièrement adapté au matériel quantique actuel. Une autre caractéristique de l'encodage de nos données en utilisant (et spécifiquement, notre choix d'utiliser l'encodage en angle sur l'axe Y) est qu'il crée des états quantiques à valeurs réelles qui peuvent être utiles pour certaines applications. Pour la rotation autour de l'axe Y, les données sont mappées avec une porte de rotation par un angle réel (Qiskit RYGate). Comme pour l'encodage en phase (voir ci-dessous), nous recommandons de redimensionner les données de sorte que , évitant ainsi la perte d'information et d'autres effets indésirables.
Le code Qiskit suivant fait pivoter un seul qubit depuis un état initial pour encoder une valeur de données .
from qiskit.quantum_info import Statevector
from math import pi
qc = QuantumCircuit(1)
state1 = Statevector.from_instruction(qc)
qc.ry(pi / 2, 0) # Phase gate rotates by an angle pi/2
state2 = Statevector.from_instruction(qc)
states = state1, state2
Nous allons définir une fonction pour visualiser l'action sur le vecteur d'état. Les détails de la définition de la fonction ne sont pas importants, mais la capacité à visualiser les vecteurs d'état et leurs changements est importante.
import numpy as np
from qiskit.visualization.bloch import Bloch
from qiskit.visualization.state_visualization import _bloch_multivector_data
def plot_Nstates(states, axis, plot_trace_points=True):
"""This function plots N states to 1 Bloch sphere"""
bloch_vecs = [_bloch_multivector_data(s)[0] for s in states]
if axis is None:
bloch_plot = Bloch()
else:
bloch_plot = Bloch(axes=axis)
bloch_plot.add_vectors(bloch_vecs)
if len(states) > 1:
def rgba_map(x, num):
g = (0.95 - 0.05) / (num - 1)
i = 0.95 - g * num
y = g * x + i
return (0.0, y, 0.0, 0.7)
num = len(states)
bloch_plot.vector_color = [rgba_map(x, num) for x in range(1, num + 1)]
bloch_plot.vector_width = 3
bloch_plot.vector_style = "simple"
if plot_trace_points:
def trace_points(bloch_vec1, bloch_vec2):
# bloch_vec = (x,y,z)
n_points = 15
thetas = np.arccos([bloch_vec1[2], bloch_vec2[2]])
phis = np.arctan2(
[bloch_vec1[1], bloch_vec2[1]], [bloch_vec1[0], bloch_vec2[0]]
)
if phis[1] < 0:
phis[1] = phis[1] + 2 * pi
angles0 = np.linspace(phis[0], phis[1], n_points)
angles1 = np.linspace(thetas[0], thetas[1], n_points)
xp = np.cos(angles0) * np.sin(angles1)
yp = np.sin(angles0) * np.sin(angles1)
zp = np.cos(angles1)
pnts = [xp, yp, zp]
bloch_plot.add_points(pnts)
bloch_plot.point_color = "k"
bloch_plot.point_size = [4] * len(bloch_plot.points)
bloch_plot.point_marker = ["o"]
for i in range(len(bloch_vecs) - 1):
trace_points(bloch_vecs[i], bloch_vecs[i + 1])
bloch_plot.sphere_alpha = 0.05
bloch_plot.frame_alpha = 0.15
bloch_plot.figsize = [4, 4]
bloch_plot.render()
plot_Nstates(states, axis=None, plot_trace_points=True)

Il s'agissait d'une seule caractéristique d'un seul vecteur de données. Lorsqu'on encode caractéristiques dans les angles de rotation de qubits, par exemple pour le vecteur de données l'état produit encodé ressemble à ceci :
On note que c'est équivalent à
Vérifie ta compréhension
Lis les questions ci-dessous, réfléchis à tes réponses, puis clique sur les triangles pour révéler les solutions.
Encode le vecteur de données en utilisant l'encodage angulaire, tel que décrit ci-dessus.
Réponse :
qc = QuantumCircuit(3)
qc.ry(0, 0)
qc.ry(2 * math.pi / 4, 1)
qc.ry(2 * math.pi / 2, 2)
qc.draw(output="mpl")

En utilisant l'encodage angulaire tel que décrit ci-dessus, combien de qubits sont nécessaires pour encoder 5 caractéristiques ?
Réponse : 5
Encodage par phase
L'encodage par phase est très similaire à l'encodage angulaire décrit ci-dessus. L'angle de phase d'un qubit est un angle réel autour de l'axe à partir de l'axe . Les données sont mappées avec une rotation de phase, , où (voir Qiskit PhaseGate pour plus d'informations). Il est recommandé de redimensionner les données de façon que . Cela évite la perte d'information et d'autres effets potentiellement indésirables[1,2].
Un qubit est souvent initialisé dans l'état , qui est un état propre de l'opérateur de rotation de phase, ce qui signifie que l'état du qubit doit d'abord être tourné pour que l'encodage par phase puisse être mis en œuvre. Il est donc judicieux d'initialiser l'état avec une porte Hadamard : . L'encodage par phase sur un seul qubit consiste à conférer une phase relative proportionnelle à la valeur de la donnée :
La procédure d'encodage par phase mappe chaque valeur de caractéristique sur la phase d'un qubit correspondant, . Au total, l'encodage par phase a une profondeur de circuit de 2, en incluant la couche Hadamard, ce qui en fait un schéma d'encodage efficace. L'état multi-qubit encodé par phase ( qubits pour caractéristiques) est un état produit :
Le code Qiskit suivant prépare d'abord l'état initial d'un seul qubit en le faisant tourner avec une porte Hadamard, puis le fait tourner à nouveau à l'aide d'une porte de phase pour encoder une caractéristique de données .
qc = QuantumCircuit(1)
qc.h(0) # Hadamard gate rotates state down to Bloch equator
state1 = Statevector.from_instruction(qc)
qc.p(pi / 2, 0) # Phase gate rotates by an angle pi/2
state2 = Statevector.from_instruction(qc)
states = state1, state2
qc.draw("mpl", scale=1)

On peut visualiser la rotation dans en utilisant la fonction plot_Nstates que nous avons définie.
plot_Nstates(states, axis=None, plot_trace_points=True)

Le tracé de la sphère de Bloch montre la rotation selon l'axe Z où . La flèche vert clair indique l'état final.
L'encodage par phase est utilisé dans de nombreuses feature maps quantiques, notamment les feature maps et , ainsi que les feature maps de Pauli générales, entre autres.
Vérifie ta compréhension
Lis les questions ci-dessous, réfléchis à tes réponses, puis clique sur les triangles pour révéler les solutions.
Combien de qubits sont nécessaires pour utiliser l'encodage par phase tel que décrit ci-dessus afin de stocker 8 caractéristiques ?
Réponse : 8
Écris du code pour encoder le vecteur en utilisant l'encodage par phase.
Réponse :
Il peut y avoir plusieurs réponses. Voici un exemple :
phase_data = [4, 8, 5, 9, 8, 6, 2, 9, 2, 5, 7, 0]
qc = QuantumCircuit(len(phase_data))
for i in range(0, len(phase_data)):
qc.h(i)
qc.rz(phase_data[i] * 2 * math.pi / float(max(phase_data)), i)
qc.draw(output="mpl")

Encodage angulaire dense
L'encodage angulaire dense (DAE) est une combinaison de l'encodage angulaire et de l'encodage par phase. Le DAE permet d'encoder deux valeurs de caractéristiques dans un seul qubit : un angle avec un angle de rotation autour de l'axe Y, et l'autre avec un angle de rotation autour de l'axe : . Il encode deux caractéristiques de la manière suivante :
L'encodage de deux caractéristiques de données dans un seul qubit permet de réduire de le nombre de qubits nécessaires pour l'encodage. En étendant cela à davantage de caractéristiques, le vecteur de données peut être encodé comme suit :
Le DAE peut être généralisé à des fonctions arbitraires des deux caractéristiques au lieu des fonctions sinusoïdales utilisées ici. On appelle cela l'encodage général de qubit[7].
À titre d'exemple de DAE, le code ci-dessous encode et visualise l'encodage des caractéristiques et .
qc = QuantumCircuit(1)
state1 = Statevector.from_instruction(qc)
qc.ry(3 * pi / 8, 0)
state2 = Statevector.from_instruction(qc)
qc.rz(7 * pi / 4, 0)
state3 = Statevector.from_instruction(qc)
states = state1, state2, state3
plot_Nstates(states, axis=None, plot_trace_points=True)

Vérifie ta compréhension
Lis les questions ci-dessous, réfléchis à tes réponses, puis clique sur les triangles pour révéler les solutions.
D'après le traitement ci-dessus, combien de qubits sont nécessaires pour encoder 6 caractéristiques avec l'encodage dense ?
Réponse : 3
Écris du code pour charger le vecteur en utilisant l'encodage angulaire dense.
Réponse :
Note que nous avons complété la liste avec un « 0 » pour éviter le problème d'un seul paramètre inutilisé dans notre schéma d'encodage.
dense_data = [4, 8, 5, 9, 8, 6, 2, 9, 2, 5, 7, 0, 3, 7, 5, 0]
qc = QuantumCircuit(int(len(dense_data) / 2))
entry = 0
for i in range(0, int(len(dense_data) / 2)):
qc.ry(dense_data[entry] * 2 * math.pi / float(max(dense_data)), i)
entry = entry + 1
qc.rz(dense_data[entry] * 2 * math.pi / float(max(dense_data)), i)
entry = entry + 1
qc.draw(output="mpl")

Encodage avec des feature maps intégrées
Encodage à des points arbitraires
L'encodage angulaire, l'encodage par phase et l'encodage dense préparent des états produits avec une feature encodée sur chaque qubit (ou deux features par qubit). C'est différent de l'encodage en base et de l'encodage en amplitude, car ces méthodes utilisent des états intriqués. Il n'y a pas de correspondance 1:1 entre feature de la donnée et qubit. Dans l'encodage en amplitude, par exemple, une feature peut être l'amplitude de l'état et une autre feature l'amplitude de . En général, les méthodes qui encodent dans des états produits donnent des circuits moins profonds et peuvent stocker 1 ou 2 features par qubit. Les méthodes qui utilisent l'intrication et associent une feature à un état plutôt qu'à un qubit produisent des circuits plus profonds, et peuvent stocker plus de features par qubit en moyenne.
Mais l'encodage n'a pas besoin d'être entièrement dans des états produits ou entièrement dans des états intriqués comme dans l'encodage en amplitude. En effet, de nombreux schémas d'encodage intégrés dans Qiskit permettent d'encoder aussi bien avant qu'après une couche d'intrication, plutôt qu'uniquement au début. C'est ce qu'on appelle le « data reuploading ». Pour des travaux connexes, voir les références [5] et [6].
Dans cette section, nous allons utiliser et visualiser quelques-uns des schémas d'encodage intégrés. Toutes les méthodes de cette section encodent features sous forme de rotations sur portes paramétrées sur qubits, où . Note que maximiser le chargement des données pour un nombre donné de qubits n'est pas la seule considération. Dans de nombreux cas, la profondeur du circuit peut être une considération encore plus importante que le nombre de qubits.
Efficient SU2
Un exemple courant et utile d'encodage avec intrication est le circuit efficient_su2 de Qiskit. Remarquablement, ce circuit peut, par exemple, encoder 8 features sur seulement 2 qubits. Voyons cela, puis essayons de comprendre comment c'est possible.
from qiskit.circuit.library import efficient_su2
circuit = efficient_su2(num_qubits=2, reps=1, insert_barriers=True)
circuit.decompose().draw(output="mpl")

Lorsque nous écrivons notre état, nous utiliserons la convention Qiskit selon laquelle les qubits les moins significatifs sont ordonnés à l'extrême droite, comme dans ou Ces états peuvent devenir très compliqués très rapidement, et ce rare exemple peut aider à expliquer pourquoi ces états sont rarement écrits explicitement.
Notre système commence dans l'état Jusqu'à la première barrière (un point que nous notons ), nos états sont :
C'est simplement de l'encodage dense, que nous avons déjà vu. Maintenant, après la porte CNOT, à la deuxième barrière (), notre état est
Nous appliquons maintenant le dernier ensemble de rotations sur qubit unique et regroupons les états similaires pour obtenir :
C'est probablement trop compliqué à analyser. Prends plutôt du recul et réfléchis au nombre de paramètres que nous avons chargés sur l'état : huit. Mais nous n'avons que quatre états de base computationnels. À première vue, il peut sembler que nous ayons chargé plus de paramètres qu'il n'est raisonnable, puisque l'état final peut s'écrire . Note cependant que chaque préfacteur est complexe ! Écrit ainsi :
On peut voir que nous avons bien, en effet, huit paramètres sur l'état sur lesquels encoder nos huit features.
En augmentant le nombre de qubits et en augmentant le nombre de répétitions des couches d'intrication et de rotation, on peut encoder beaucoup plus de données. Écrire les fonctions d'onde devient rapidement intraitable. Mais on peut toujours voir l'encodage en action.
Ici nous encodons le vecteur de données avec 12 features, sur un circuit efficient_su2 à 3 qubits, en utilisant chacune des portes paramétrées pour encoder une feature différente.
Dans ce vecteur de données, les features sont présentées dans un ordre particulier. Isolément, peu importe si elles sont encodées dans cet ordre ou dans l'ordre inverse. Ce qui est important, c'est de garder une trace de cet ordre et d'être cohérent. Note dans le diagramme du circuit que efficient_su2 suppose un certain ordre d'encodage, à savoir remplir la première couche de portes paramétrées du qubit 0 au qubit 2, puis passer à la couche suivante. Cela n'est ni cohérent ni incohérent avec la notation little-endian, puisqu'ici les features de données ne peuvent pas être ordonnées par qubit a priori, avant qu'un circuit d'encodage ait été spécifié.
x = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0, 1.1, 1.2]
circuit = efficient_su2(num_qubits=3, reps=1, insert_barriers=True)
encode = circuit.assign_parameters(x)
encode.decompose().draw(output="mpl")

Au lieu d'augmenter le nombre de qubits, tu peux choisir d'augmenter le nombre de répétitions des couches d'intrication et de rotation. Mais il y a des limites au nombre de répétitions utiles. Comme dit précédemment, il y a un compromis : les circuits avec plus de qubits ou plus de répétitions des couches d'intrication et de rotation peuvent stocker plus de paramètres, mais le font avec une plus grande profondeur de circuit. Nous reviendrons sur les profondeurs de quelques feature maps intégrées ci-dessous. Les prochaines méthodes d'encodage intégrées dans Qiskit ont « feature map » dans leur nom. Rappelons qu'encoder des données dans un circuit quantique est un feature mapping, dans le sens où il amène les données dans un nouvel espace : l'espace de Hilbert des qubits concernés. La relation entre la dimensionnalité de l'espace de features original et celle de l'espace de Hilbert dépendra du circuit utilisé pour l'encodage.
Feature map
La feature map (ZFM) peut être interprétée comme une extension naturelle de l'encodage par phase. La ZFM est constituée de couches alternées de portes à qubit unique : des couches de portes Hadamard et des couches de portes de phase. Soit le vecteur de données avec features. Le circuit quantique qui réalise le feature mapping est représenté par un opérateur unitaire qui agit sur l'état initial :
où est l'état fondamental à qubits. Cette notation est utilisée par cohérence avec la référence [4] Havlicek et al. Les features des données sont associées une à une aux qubits correspondants. Par exemple, si tu as 8 features dans un vecteur de données, tu utiliserais 8 qubits. Le circuit ZFM est composé de répétitions d'un sous-circuit comprenant des couches de portes Hadamard et des couches de portes de phase. Une couche Hadamard est composée d'une porte Hadamard agissant sur chaque qubit d'un registre à qubits, , à la même étape de l'algorithme. Cette description s'applique également à une couche de portes de phase dans laquelle le qubit est actionné par . Chaque porte prend une feature comme argument, mais la couche de portes de phase ( est une fonction du vecteur de données. L'unitaire complet du circuit ZFM avec une seule répétition est :
Alors répétitions de cet unitaire donneraient
Les features des données sont associées aux portes de phase de la même façon dans toutes les répétitions. L'état de la feature map ZFM est un état produit et est efficacement simulable classiquement[4].
Pour commencer par un petit exemple, un circuit ZFM à deux qubits est codé avec Qiskit et dessiné pour afficher la structure simple du circuit. Dans l'exemple, une seule répétition, , est implémentée avec le vecteur de données . Note que ceci est écrit dans l'ordre standard d'un vecteur en Python, ce qui signifie que l'élément d'indice est Nous sommes libres d'encoder cette feature d'indice sur notre qubit d'indice , ou sur notre qubit d'indice . Encore une fois, il ne peut pas toujours y avoir un seul mapping 1:1 de l'ordre des features vers l'ordre des qubits, car différentes feature maps encodent différents nombres de features sur chaque qubit. Ce qui est important, encore une fois, c'est que nous sachions où chaque feature est encodée. Lorsqu'on fournit une liste de paramètres à la feature map , elle encodera la feature 0 de la liste sur le qubit le moins significatif disposant d'une porte paramétrée, c'est-à-dire le qubit 0. Nous suivrons donc cette convention lorsque nous le faisons à la main. Nous encoderons sur le qubit d'indice , et sur le qubit d'indice .
L'opérateur unitaire du circuit ZFM agit sur l'état initial de la façon suivante :
La formule a été réorganisée autour du produit tensoriel pour mettre en évidence les opérations sur chaque qubit. Le code Qiskit suivant utilise explicitement des portes Hadamard et de phase pour montrer la structure de la ZFM :
qc0 = QuantumCircuit(1)
qc1 = QuantumCircuit(1)
qc0.h(0)
qc0.p(pi / 2, 0)
qc1.h(0)
qc1.p(pi / 3, 0)
# Combine circuits qc0 and qc1 into 1 circuit
qc = QuantumCircuit(2)
qc.compose(qc0, [0], inplace=True)
qc.compose(qc1, [1], inplace=True)
qc.draw("mpl", scale=1)

Nous encodons maintenant le même vecteur de données dans un circuit ZFM avec trois répétitions, , en utilisant la classe Qiskit z_feature_map, ce qui nous donne au total la feature map quantique . Par défaut dans la classe z_feature_map, les paramètres sont multipliés par 2 avant d'être associés à la porte de phase . Pour reproduire les mêmes encodages que ci-dessus, nous divisons par 2.
from qiskit.circuit.library import z_feature_map
zfeature_map = z_feature_map(feature_dimension=2, reps=3)
zfeature_map = zfeature_map.assign_parameters([(1 / 2) * pi / 2, (1 / 2) * pi / 3])
zfeature_map.decompose().draw("mpl")

C'est clairement un mapping différent de celui fait à la main plus haut, mais note la cohérence dans l'ordre des paramètres : a de nouveau été encodé sur le qubit d'indice .
Tu peux utiliser la ZFM via la classe ZFM de Qiskit ; tu peux aussi utiliser cette structure comme inspiration pour construire ta propre feature map.
Feature map
La feature map (ZZFM) étend la ZFM avec l'inclusion de portes d'intrication à deux qubits, plus précisément la porte de rotation , . La ZZFM est supposée être généralement coûteuse à calculer sur un ordinateur classique, contrairement à la ZFM.
implémente une interaction et est maximalement intriquante pour . peut être décomposée en une série de portes sur deux qubits, comme montré dans le code Qiskit suivant en utilisant la porte RZZ et la méthode decompose de la classe QuantumCircuit. Nous encodons une seule feature du vecteur de données :
qc = QuantumCircuit(2)
qc.rzz(pi, 0, 1)
qc.draw("mpl", scale=1)

Comme c'est souvent le cas, nous voyons cela représenté comme une unité de type porte unique, jusqu'à ce que nous utilisions .decompose() pour voir toutes les portes constitutives.
qc.decompose().draw("mpl", scale=1)

Les données sont associées à une rotation de phase sur le second qubit. La porte intrique les deux qubits sur lesquels elle opère, avec un degré d'intrication déterminé par la valeur de la feature encodée.
Le circuit ZZFM complet est constitué d'une porte Hadamard et d'une porte de phase, comme dans la ZFM, suivies de l'intrication décrite ci-dessus. Une seule répétition du circuit ZZFM est :
où contient une couche de portes ZZ structurée par un schéma d'intrication. Plusieurs schémas d'intrication sont présentés dans les blocs de code ci-dessous. La structure de inclut également une fonction qui combine les features de données des qubits intriqués de la façon suivante. Disons que la porte doit être appliquée aux qubits et . Dans la couche de phase, ces qubits ont des portes de phase qui encodent et sur eux, respectivement. L'argument de ne sera pas simplement l'une de ces features ou l'autre, mais une fonction souvent notée (à ne pas confondre avec l'angle azimutal) :
Nous verrons cela dans plusieurs exemples ci-dessous. L'extension à plusieurs répétitions est la même que dans le cas de la z_feature_map :
Les opérateurs ayant gagné en complexité, encodons d'abord un vecteur de données avec une ZZFM à deux qubits et une répétition avec le code suivant :
from qiskit.circuit.library import zz_feature_map
feature_dim = 2
zzfeature_map = zz_feature_map(
feature_dimension=feature_dim, entanglement="linear", reps=1
)
zzfeature_map.decompose(reps=1).draw("mpl", scale=1)

Par défaut dans Qiskit, les features sont combinées dans par cette fonction de mapping . Qiskit permet à l'utilisateur de personnaliser la fonction (ou où est l'ensemble des paires de qubits couplés via les portes ) comme étape de prétraitement.
En passant à un vecteur de données à quatre dimensions et en l'associant à une ZZFM à quatre qubits avec une répétition, nous pouvons commencer à voir le mapping pour diverses paires de qubits. Nous pouvons également voir la signification de l'intrication « linéaire » :
feature_dim = 4
zzfeature_map = zz_feature_map(
feature_dimension=feature_dim, entanglement="linear", reps=1
)
zzfeature_map.decompose().draw("mpl", scale=1)

Dans le schéma d'intrication linéaire, les paires de qubits voisins (numérotés) de ce circuit sont intriqués. Il existe d'autres schémas d'intrication intégrés dans Qiskit, notamment circular et full.
Feature map de Pauli
La feature map de Pauli (PFM) est la généralisation de la ZFM et de la ZZFM à l'utilisation de portes de Pauli arbitraires. La PFM prend une forme très similaire aux deux feature maps précédentes. Pour répétitions de l'encodage des features du vecteur
Pour la PFM, est généralisé en un opérateur unitaire d'expansion de Pauli. Nous présentons ici une forme plus générale des feature maps étudiées jusqu'à présent :
où est un opérateur de Pauli, . Ici est l'ensemble de toutes les connectivités de qubits telles que déterminées par la feature map, incluant l'ensemble des qubits actionnés par des portes à qubit unique. C'est-à-dire que pour une feature map dans laquelle le qubit 0 est actionné par une porte de phase, et les qubits 2 et 3 par une porte , l'ensemble inclurait . parcourt tous les éléments de cet ensemble. Dans les feature maps précédentes, la fonction était impliquée soit exclusivement avec des portes à qubit unique, soit exclusivement avec des portes à deux qubits. Ici, nous la définissons de façon générale :
Pour la documentation, voir la documentation de la classe Qiskit Pauli feature map). Dans la ZZFM, l'opérateur est restreint à .
Une façon de comprendre l'unitaire ci-dessus est par analogie avec le propagateur dans un système physique. L'unitaire ci-dessus est un opérateur d'évolution unitaire, , pour un Hamiltonien, , similaire au modèle d'Ising, où le paramètre de temps, , est remplacé par des valeurs de données pour piloter l'évolution. Le développement de cet opérateur unitaire donne le circuit PFM. Les connectivités d'intrication dans peuvent être interprétées comme des couplages d'Ising dans un réseau de spins.
Considérons un exemple avec les opérateurs de Pauli et représentant ces interactions de type Ising. Qiskit fournit une classe pauli_feature_map pour instancier une PFM avec un choix de portes à qubit unique et à qubits, qui dans cet exemple seront passées sous forme de chaînes de Pauli 'Y' et 'XX'. En général, vaut 1 ou 2 pour des interactions à un ou deux qubits, respectivement. Le schéma d'intrication est « linéaire », ce qui signifie que seuls les qubits voisins dans le circuit quantique sont couplés. Note que cela ne correspond pas aux qubits voisins sur l'ordinateur quantique lui-même, car ce circuit quantique est une couche d'abstraction.
from qiskit.circuit.library import pauli_feature_map
feature_dim = 3
pfmap = pauli_feature_map(
feature_dimension=feature_dim, entanglement="linear", reps=1, paulis=["Y", "XX"]
)
pfmap.decompose().draw("mpl", scale=1.5)

Qiskit fournit un paramètre, , dans les feature maps de Pauli pour contrôler l'échelle des rotations de Pauli.
La valeur par défaut de est . En optimisant sa valeur dans l'intervalle, par exemple, on peut mieux aligner un noyau quantique aux données.
Galerie de feature maps de Pauli
Ici nous visualisons diverses feature maps de Pauli pour des circuits à deux qubits, afin d'avoir une meilleure idée de l'éventail des possibilités.
from qiskit.visualization import circuit_drawer
import matplotlib.pyplot as plt
feature_dim = 2
fig, axs = plt.subplots(9, 2)
i_plot = 0
for paulis in [
["I"],
["X"],
["Y"],
["Z"],
["XX"],
["XY"],
["XZ"],
["YY"],
["YZ"],
["ZZ"],
["X", "ZZ"],
["Y", "ZZ"],
["Z", "ZZ"],
["X", "YZ"],
["Y", "YZ"],
["Z", "YZ"],
["YY", "ZZ"],
["XY", "ZZ"],
]:
pfmap = pauli_feature_map(feature_dimension=feature_dim, paulis=paulis, reps=1)
circuit_drawer(
pfmap.decompose(),
output="mpl",
style={"backgroundcolor": "#EEEEEE"},
ax=axs[int((i_plot - i_plot % 2) / 2), i_plot % 2],
)
axs[int((i_plot - i_plot % 2) / 2), i_plot % 2].title.set_text(paulis)
i_plot += 1
fig.set_figheight(16)
fig.set_figwidth(16)
Ce qui précède peut bien sûr être étendu pour inclure d'autres permutations et répétitions de matrices de Pauli. Les apprenants sont encouragés à expérimenter avec ces options.
Récapitulatif des feature maps intégrées
Tu as vu plusieurs schémas pour encoder des données dans un circuit quantique :
- Encodage en base
- Encodage en amplitude
- Encodage angulaire
- Encodage par phase
- Encodage dense
Tu as vu comment construire tes propres feature maps en utilisant ces schémas d'encodage, et tu as vu quatre feature maps intégrées qui tirent parti de l'encodage angulaire et de l'encodage par phase :
- Efficient SU2
- Feature map Z
- Feature map ZZ
- Feature map de Pauli
Ces feature maps intégrées diffèrent les unes des autres de plusieurs façons :
- La profondeur pour un nombre donné de features encodées
- Le nombre de qubits nécessaires pour un nombre donné de features
- Le degré d'intrication (évidemment lié aux autres différences)
Le code ci-dessous applique ces quatre feature maps intégrées à l'encodage d'un ensemble de features, et trace la profondeur à deux qubits du circuit résultant. Étant donné que les taux d'erreur à deux qubits sont bien plus élevés que les taux d'erreur des portes à qubit unique, on pourrait raisonnablement s'intéresser en priorité à la profondeur des portes à deux qubits. Dans le code ci-dessous, nous obtenons le nombre de toutes les portes d'un circuit en décomposant d'abord le circuit puis en utilisant count_ops(), comme indiqué. Ici, les portes à deux qubits qui nous intéressent sont les portes 'cx' :
# Initializing parameters and empty lists for depths
x = [0.1, 0.2]
n_data = []
zz2gates = []
su22gates = []
z2gates = []
p2gates = []
# Generating feature maps
for n in range(3, 10):
x.append(n / 10)
zzcircuit = zz_feature_map(n, reps=1, insert_barriers=True)
zcircuit = z_feature_map(n, reps=1, insert_barriers=True)
su2circuit = efficient_su2(n, reps=1, insert_barriers=True)
pcircuit = pauli_feature_map(n, reps=1, paulis=["XX"], insert_barriers=True)
# Getting the cx depths
zzcx = zzcircuit.decompose().count_ops().get("cx")
zcx = zcircuit.decompose().count_ops().get("cx")
su2cx = su2circuit.decompose().count_ops().get("cx")
pcx = pcircuit.decompose().count_ops().get("cx")
# Appending the cx gate counts to the lists. We shift the zz and Pauli data points,
# because they overlap.
n_data.append(n)
zz2gates.append(zzcx - 0.5)
z2gates.append(0)
su22gates.append(su2cx)
p2gates.append(pcx + 0.5)
# Plot the output
plt.plot(n_data, p2gates, "bo")
plt.plot(n_data, zz2gates, "ro")
plt.plot(n_data, su22gates, "yo")
plt.plot(n_data, z2gates, "go")
plt.ylabel("CX Gates")
plt.xlabel("Data elements")
plt.legend(["Pauli", "ZZ", "SU2", "Z"])
# plt.suptitle('zz_feature_map(n)')
plt.show()
En général, les feature maps Pauli et ZZ entraîneront une profondeur de circuit plus grande et un plus grand nombre de portes à 2 qubits que les feature maps efficient_su2 et Z.
Étant donné que les feature maps intégrées dans Qiskit sont largement applicables, nous n'aurons souvent pas besoin de concevoir les nôtres, surtout en phase d'apprentissage. Cependant, les experts en apprentissage automatique quantique reviendront probablement sur la conception de leur propre feature mapping, lorsqu'ils s'attaqueront à deux défis complexes :
-
Le matériel moderne : la présence du bruit et le surcoût important des codes correcteurs d'erreurs signifient que les applications actuelles devront tenir compte de choses comme l'efficacité matérielle et la minimisation de la profondeur des portes à deux qubits.
-
Des mappings adaptés au problème en question : c'est une chose de dire que la
zz_feature_map, par exemple, est difficile à simuler classiquement, et donc intéressante. C'en est une autre que lazz_feature_mapsoit idéalement adaptée à ta tâche d'apprentissage automatique ou à ton jeu de données. La performance des différents circuits quantiques paramétrés sur différents types de données est un domaine de recherche actif.
Nous concluons avec une note sur l'efficacité matérielle.
Feature mapping efficace pour le matériel
Un feature mapping efficace pour le matériel est un mapping qui tient compte des contraintes des vrais ordinateurs quantiques, dans le but de réduire le bruit et les erreurs dans le calcul. Lors de l'exécution de circuits quantiques sur des ordinateurs quantiques à court terme, il existe de nombreuses stratégies pour atténuer le bruit inhérent au matériel. L'une des principales stratégies pour l'efficacité matérielle est la minimisation de la profondeur du circuit quantique afin que le bruit et la décohérence aient moins de temps pour corrompre le calcul. La profondeur d'un circuit quantique est le nombre d'étapes de portes alignées temporellement nécessaires pour compléter l'ensemble du calcul (après optimisation du circuit)[5]. Rappelle-toi que la profondeur du circuit abstrait et logique peut être bien inférieure à la profondeur une fois le circuit transpilé pour un vrai ordinateur quantique.
La transpilation est le processus de conversion du circuit quantique d'une abstraction de haut niveau vers un circuit prêt à s'exécuter sur un vrai ordinateur quantique, en tenant compte des contraintes du matériel. Un ordinateur quantique possède un ensemble natif de portes à un et deux qubits. Cela signifie que toutes les portes du code Qiskit doivent être transpilées vers l'ensemble des portes matérielles natives. Par exemple, dans ibm_torino, un QPU doté d'un processeur Heron r1 et mis en service en 2023, les portes natives ou de base sont {CZ, ID, RZ, SX, X}. Ce sont respectivement la porte à deux qubits CZ contrôlée, et les portes à qubit unique appelées identité, rotation-, racine carrée de NOT, et NOT, fournissant un ensemble universel. Lors de l'implémentation de portes multi-qubits sous forme de sous-circuit équivalent, des portes physiques à deux qubits sont nécessaires, ainsi que d'autres portes à qubit unique disponibles dans le matériel. De plus, pour effectuer une porte à deux qubits sur une paire de qubits qui ne sont pas physiquement couplés, des portes SWAP sont ajoutées pour déplacer les états des qubits entre les qubits afin de permettre le couplage, ce qui entraîne une extension inévitable du circuit. En utilisant l'argument optimization qui peut être réglé de 0 jusqu'à un niveau maximum de 3. Pour plus de contrôle et de personnalisation, le pipeline du transpileur peut être géré avec le Qiskit Pass Manager. Réfère-toi à la documentation du transpileur Qiskit pour plus d'informations sur la transpilation.
Dans Havlicek et al. 2019 [2], une façon dont les auteurs obtiennent l'efficacité matérielle est d'utiliser la feature map car c'est un développement du second ordre (voir la section « Feature map » ci-dessus). Un développement d'ordre comporte des portes à qubits. Les ordinateurs quantiques IBM® n'ont pas de portes natives à qubits pour , donc pour les implémenter il faudrait les décomposer en portes CNOT à deux qubits disponibles dans le matériel. Une deuxième façon dont les auteurs minimisent la profondeur est en choisissant une topologie de couplage qui se mappe directement sur les couplages de l'architecture. Une optimisation supplémentaire qu'ils effectuent est de cibler un sous-circuit matériel plus performant et convenablement connecté. D'autres éléments à considérer sont la minimisation du nombre de répétitions de la feature map et le choix d'un schéma d'intrication personnalisé à faible profondeur ou « linéaire » plutôt que le schéma « full » qui intrique tous les qubits.

Le graphique ci-dessus montre un réseau de nœuds et d'arêtes représentant respectivement des qubits physiques et des couplages matériels. La carte de couplage et les performances d'ibm_torino sont affichées avec toutes les portes de couplage CZ à deux qubits possibles. Les qubits sont codés par couleur sur une échelle basée sur le temps de relaxation T1 en microsecondes (μs), où des temps T1 plus longs sont meilleurs et apparaissent dans une teinte plus claire. Les arêtes de couplage sont codées par couleur en fonction de l'erreur CZ, où les teintes plus foncées sont meilleures. Les informations sur la spécification du matériel sont accessibles dans le schéma de configuration du backend matériel IBMQBackend.configuration().
Références
- Maria Schuld and Francesco Petruccione, Supervised Learning with Quantum Computers, Springer 2018, doi:10.1007/978-3-319-96424-9.
- Vojtech Havlicek et al., "Supervised Learning with Quantum Enhanced Feature Spaces." Nature, vol. 567 (2019): 209–212. https://arxiv.org/abs/1804.11326.
- Ryan LaRose and Brian Coyle, "Robust data encodings for quantum classifiers", Physical Review A 102, 032420 (2020), doi:10.1103/PhysRevA.102.032420, arXiv:2003.01695.
- Lou Grover and Terry Rudolph. "Creating Superpositions That Correspond to Efficiently Integrable Probability Distributions." arXiv:quant-ph/0208112, August 15, 2002, https://arxiv.org/abs/quant-ph/0208112.
- Adrián Pérez-Salinas, Alba Cervera-Lierta, Elies Gil-Fuster, José I. Latorre, "Data re-uploading for a universal quantum classifier", Quantum 4, 226 (2020), ArXiv.org/abs/1907.02085.
- Maria Schuld, Ryan Sweke, Johannes Jakob Meyer, "The effect of data encoding on the expressive power of variational quantum machine learning models", Phys. Rev. A 103, 032430 (2021), arxiv.org/abs/2008.08605
import qiskit
qiskit.version.get_version_info()