Intrication à longue portée avec des circuits dynamiques
Estimation d'utilisation : 4 minutes sur un processeur Heron r2. (REMARQUE : Il ne s'agit que d'une estimation. Votre temps d'exécution peut varier.)
Résultats d'apprentissage
Après avoir suivi ce tutoriel, tu auras appris ce qui suit :
- Comment implémenter une porte CNOT à longue portée à l'aide de circuits dynamiques avec des mesures en milieu de circuit (MCM) et du feedforward classique ;
- Comment implémenter la porte équivalente en utilisant une approche unitaire basée sur des SWAP ;
- Comment comparer les deux approches en mesurant la fidélité de porte en fonction de la distance entre les qubits.
Prérequis
Nous suggérons aux utilisateurs d'être familiers avec les sujets suivants avant de suivre ce tutoriel :
- Concepts de base de l'informatique quantique, notamment les états de Bell, l'intrication et les portes quantiques ;
- La maîtrise des circuits dynamiques (mesures en milieu de circuit et feedforward classique) ;
- Des connaissances de base du SDK Qiskit et de Qiskit Runtime, ainsi qu'un accès à un compte IBM Quantum®.
Contexte
L'intrication à longue portée entre des qubits distants est un défi sur les dispositifs à connectivité limitée. Ce tutoriel montre comment les circuits dynamiques peuvent générer une telle intrication en implémentant une porte controlled-X à longue portée (LRCX) à l'aide d'un protocole basé sur la mesure.
En suivant l'approche d'Elisa Bäumer et al. dans 1, la méthode utilise des mesures en milieu de circuit et du feedforward pour obtenir des portes à profondeur constante, quelle que soit la séparation entre les qubits. Elle crée des paires de Bell intermédiaires, mesure un qubit de chaque paire et applique des portes conditionnées classiquement pour propager l'intrication à travers le dispositif. Cela évite les longues chaînes de SWAP, réduisant à la fois la profondeur du circuit et l'exposition aux erreurs de portes à deux qubits.
Dans ce notebook, nous adaptons le protocole pour le matériel IBM Quantum et évaluons ses performances en fonction de la séparation contrôle–cible, en le comparant à une référence unitaire basée sur des SWAP.
Prérequis d'installation
Avant de commencer ce tutoriel, assure-toi que les éléments suivants sont installés :
- Qiskit SDK v2.0 ou ultérieur, avec le support de visualisation
- Qiskit Runtime v0.37 ou ultérieur (
pip install qiskit-ibm-runtime) - Qiskit Aer v0.17 ou ultérieur (
pip install qiskit-aer)
Configuration
# Added by doQumentation — required packages for this notebook
!pip install -q matplotlib numpy qiskit qiskit-aer qiskit-ibm-runtime
from qiskit import QuantumCircuit, QuantumRegister, ClassicalRegister
from qiskit.circuit.classical import expr
from qiskit.transpiler import generate_preset_pass_manager
from qiskit.visualization import plot_circuit_layout
from qiskit_ibm_runtime import (
QiskitRuntimeService,
Batch,
SamplerV2 as Sampler,
)
import matplotlib.pyplot as plt
import numpy as np
Exemple de simulateur à petite échelle
Avant d'exécuter sur le QPU réel, nous vérifions que les circuits dynamiques et unitaires produisent un état de Bell idéal sur un simulateur sans bruit. Nous utilisons le Sampler de Qiskit Runtime avec AerSimulator comme mode de backend, pour une petite distance de 6.
Étape 1 : Transposer les entrées classiques en un problème quantique
Nous implémentons maintenant une porte CNOT à longue portée entre deux qubits distants, en suivant la construction par circuit dynamique illustrée ci-dessous (adaptée de la Fig. 1a de la Réf. 1). L'idée clé est d'utiliser un « bus » de qubits ancillaires, initialisés à , pour servir de médiateur à la téléportation de porte à longue portée.
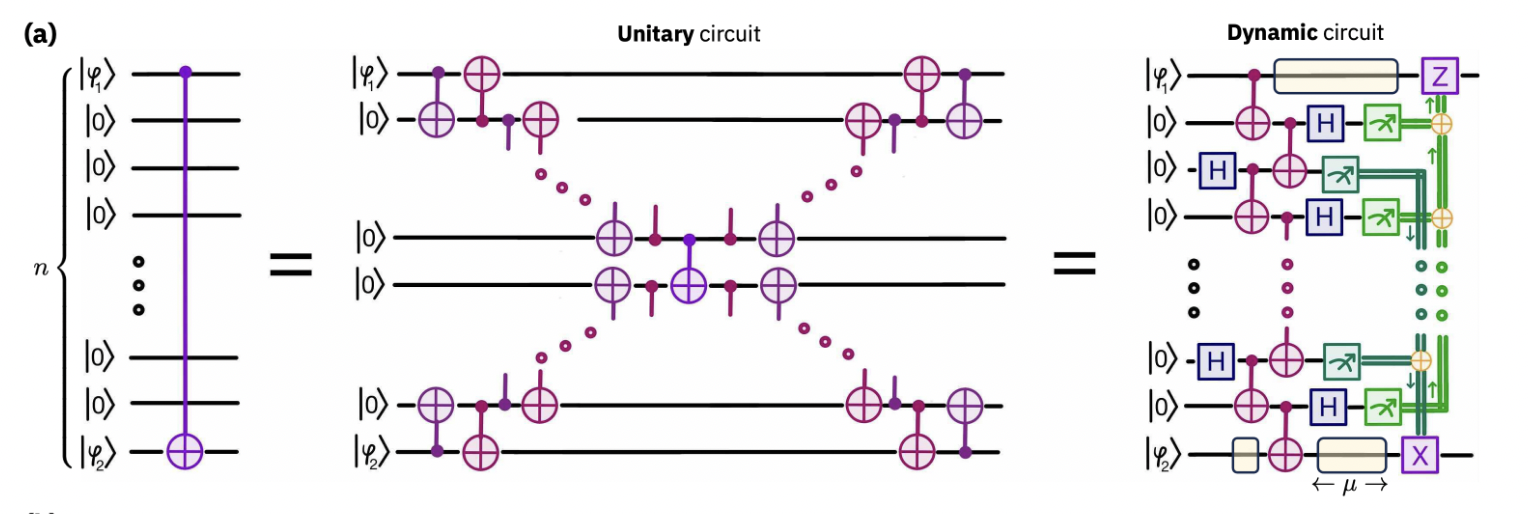
Comme illustré dans la figure, le processus fonctionne comme suit :
- Préparer une chaîne de paires de Bell reliant les qubits de contrôle et cible via des ancillaires intermédiaires.
- Effectuer des mesures de Bell entre des qubits voisins non intriqués, transférant l'intrication étape par étape jusqu'à ce que le contrôle et la cible partagent une paire de Bell.
- Utiliser cette paire de Bell pour la téléportation de porte, transformant un CNOT local en un CNOT déterministe à longue portée en profondeur constante.
Cette approche remplace les longues chaînes de SWAP par un protocole à profondeur constante, réduisant l'exposition aux erreurs de portes à deux qubits et rendant l'opération extensible avec la taille du dispositif.
Dans ce qui suit, nous détaillerons d'abord l'implémentation par circuit dynamique du circuit LRCX. À la fin, nous fournirons également une implémentation unitaire à des fins de comparaison, afin de mettre en évidence les avantages des circuits dynamiques dans ce contexte.
Initialiser le circuit
Nous commençons par un problème quantique simple qui servira de base de comparaison. Plus précisément, nous initialisons un circuit avec un qubit de contrôle à l'indice 0 et lui appliquons une porte de Hadamard. Cela produit un état de superposition qui, suivi d'une opération controlled-X, génère un état de Bell entre les qubits de contrôle et cible.
À ce stade, nous ne construisons pas encore le controlled-X à longue portée (LRCX) lui-même. Notre objectif est plutôt de définir un circuit initial clair et minimal qui met en évidence le rôle du LRCX. À l'étape 2, nous montrerons comment le LRCX peut être implémenté en tant qu'optimisation à l'aide de circuits dynamiques, et comparerons ses performances avec un équivalent unitaire. Il est important de noter que le protocole LRCX peut être appliqué à n'importe quel circuit initial. Ici, nous utilisons cette configuration simple avec Hadamard pour la clarté de la démonstration.
distance = 6 # The distance of the CNOT gate, with the convention that a distance of zero is a nearest-neighbor CNOT.
def initialize_circuit(distance):
assert distance >= 0
control = 0 # control qubit
n = distance # number of qubits between target and control
qr = QuantumRegister(
n + 2, name="q"
) # Circuit with n qubits between control and target
cr = ClassicalRegister(
2, name="cr"
) # Classical register for measuring control and target qubits
k = int(n / 2) # Number of Bell States to be used
allcr = [cr]
if (
distance > 1
): # This classical register will be used to store ZZ measurements.
# It is only used for long-range CX gates with distance > 1
c1 = ClassicalRegister(
k, name="c1"
) # Classical register needed for post processing
allcr.append(c1)
if (
distance > 0
): # This classical register will be used to store XX measurements.
# It is only used if distance > 0
c2 = ClassicalRegister(
n - k, name="c2"
) # Classical register needed for post processing
allcr.append(c2)
qc = QuantumCircuit(qr, *allcr, name="CNOT")
# Apply a Hadamard gate to the control qubit such that the
# long-range CNOT gate will prepare a
# Bell state (|00> + |11>)/sqrt(2)
qc.h(control)
return qc
qc = initialize_circuit(distance)
qc.draw(fold=-1, output="mpl", scale=0.5)

Étape 2 : Optimiser le problème pour l'exécution sur du matériel quantique
Dans cette étape, nous montrons comment construire le circuit LRCX à l'aide de circuits dynamiques. L'objectif est d'optimiser le circuit pour l'exécution sur du matériel en réduisant la profondeur par rapport à une implémentation purement unitaire. Pour illustrer les avantages, nous afficherons à la fois la construction LRCX dynamique et son équivalent unitaire, puis comparerons leurs performances après transpilation. Il est important de noter que, bien que nous appliquions ici le LRCX à un problème simple initialisé par Hadamard, le protocole peut être appliqué à tout circuit nécessitant un CNOT à longue portée.
Préparer les paires de Bell
Nous commençons par créer une chaîne de paires de Bell le long du chemin entre les qubits de contrôle et cible. Si la distance est impaire, nous appliquons d'abord un CNOT du contrôle vers son voisin, qui est le CNOT qui sera téléporté. Pour une distance paire, ce CNOT sera appliqué après l'étape de préparation des paires de Bell. La chaîne de paires de Bell intriquera ensuite des paires successives de qubits, établissant la ressource nécessaire pour transporter l'information de contrôle à travers le dispositif.
# Determine where to start the Bell pair chain and add an extra CNOT when n is odd
def check_even(n: int) -> int:
"""Return 1 if n is even, else 2."""
return 1 if n % 2 == 0 else 2
def prepare_bell_pairs(qc, add_barriers=True):
n = qc.num_qubits - 2 # number of qubits between target and control
k = int(n / 2)
if add_barriers:
qc.barrier()
x0 = check_even(n)
if n % 2 != 0:
qc.cx(0, 1)
# Create k Bell pairs
for i in range(k):
qc.h(x0 + 2 * i)
qc.cx(x0 + 2 * i, x0 + 2 * i + 1)
return qc
qc = prepare_bell_pairs(qc)
qc.draw(output="mpl", fold=-1, scale=0.5)

Mesurer les paires de qubits voisins dans la base de Bell
Ensuite, nous mesurons des qubits voisins non intriqués dans la base de Bell (mesures à deux qubits de et ). Cela crée une paire de Bell à longue portée entre le qubit cible et le qubit adjacent au contrôle (à des corrections de Pauli près, qui seront implémentées via feedforward à l'étape suivante). En parallèle, nous implémentons la mesure intriquante qui téléporte la porte CNOT pour agir sur le qubit cible visé.
def measure_bell_basis(qc, add_barriers=True):
n = qc.num_qubits - 2 # number of qubits between target and control
k = int(n / 2)
if n > 1:
_, c1, c2 = qc.cregs
elif n > 0:
_, c2 = qc.cregs
# Determine where to start the Bell pair chain and add an extra CNOT
# when n is odd
x0 = 1 if n % 2 == 0 else 2
# Entangling layer that implements the Bell measurement
# (and additionally adds the CNOT to be
# teleported, if n is even)
for i in range(k + 1):
qc.cx(x0 - 1 + 2 * i, x0 + 2 * i)
for i in range(1, k + x0):
if i == 1:
qc.h(2 * i + 1 - x0)
else:
qc.h(2 * i + 1 - x0)
if add_barriers:
qc.barrier()
# Map the ZZ measurements onto classical register c1
for i in range(k):
if i == 0:
qc.measure(2 * i + x0, c1[i])
else:
qc.measure(2 * i + x0, c1[i])
# Map the XX measurements onto classical register c2
for i in range(1, k + x0):
if i == 1:
qc.measure(2 * i + 1 - x0, c2[i - 1])
else:
qc.measure(2 * i + 1 - x0, c2[i - 1])
return qc
qc = measure_bell_basis(qc)
qc.draw(output="mpl", fold=-1, scale=0.5)

Appliquer les corrections par feedforward pour corriger les opérateurs sous-produits de Pauli
Les mesures dans la base de Bell introduisent des sous-produits de Pauli qui doivent être corrigés à l'aide des résultats enregistrés. Cela se fait en deux étapes. Premièrement, nous devons calculer la parité de toutes les mesures , qui est ensuite utilisée pour appliquer conditionnellement une porte au qubit cible. De même, la parité des mesures est calculée et utilisée pour appliquer conditionnellement une porte au qubit de contrôle.
Avec le nouveau cadre d'expressions classiques de Qiskit, ces parités peuvent être calculées directement dans la couche de traitement classique du circuit. Au lieu d'appliquer une séquence de portes conditionnelles individuelles pour chaque bit de mesure, nous pouvons construire une seule expression classique représentant le XOR (parité) de tous les résultats de mesure pertinents. Cette expression est ensuite utilisée comme condition dans un seul bloc if_test, permettant d'appliquer les portes de correction en profondeur constante. Cette approche simplifie le circuit et garantit que les corrections par feedforward n'introduisent pas de latence supplémentaire inutile.
def apply_ffwd_corrections(qc):
control = 0 # control qubit
target = qc.num_qubits - 1 # target qubit
n = qc.num_qubits - 2 # number of qubits between target and control
k = int(n / 2)
x0 = check_even(n)
if n > 1:
_, c1, c2 = qc.cregs
elif n > 0:
_, c2 = qc.cregs
# First, let's compute the parity of all ZZ measurements
for i in range(k):
if i == 0:
parity_ZZ = expr.lift(
c1[i]
) # Store the value of the first ZZ measurement in parity_ZZ
else:
parity_ZZ = expr.bit_xor(
c1[i], parity_ZZ
) # Successively compute the parity via XOR operations
for i in range(1, k + x0):
if i == 1:
parity_XX = expr.lift(
c2[i - 1]
) # Store the value of the first XX measurement in parity_XX
else:
parity_XX = expr.bit_xor(
c2[i - 1], parity_XX
) # Successively compute the parity via XOR operations
if n > 0:
with qc.if_test(parity_XX):
qc.z(control)
if n > 1:
with qc.if_test(parity_ZZ):
qc.x(target)
return qc
qc = apply_ffwd_corrections(qc)
qc.draw(output="mpl", fold=-1, scale=0.5)

Mesurer les qubits de contrôle et cible
Nous définissons une fonction utilitaire qui permet de mesurer les qubits de contrôle et cible dans les bases , ou . Pour vérifier l'état de Bell , les valeurs moyennes de et doivent toutes deux être , car ce sont des stabilisateurs de l'état. La mesure est également prise en charge ici et sera utilisée ci-dessous lors du calcul de la fidélité.
def measure_in_basis(qc, basis="XX", add_barrier=True):
control = 0 # control qubit
target = qc.num_qubits - 1 # target qubit
assert basis in ["XX", "YY", "ZZ"]
qc = (
qc.copy()
) # We copy the circuit because we want to measure in different bases
cr = qc.cregs[0]
if add_barrier:
qc.barrier()
if basis == "XX":
qc.h(control)
qc.h(target)
elif basis == "YY":
qc.sdg(control)
qc.sdg(target)
qc.h(control)
qc.h(target)
qc.measure(control, cr[0])
qc.measure(target, cr[1])
return qc
qc_YY = measure_in_basis(qc.copy(), basis="YY")
qc_YY.draw(
output="mpl", fold=-1, scale=0.5
) # Circuit for measuring in the YY basis

Assemblage complet
Nous combinons les différentes étapes définies ci-dessus pour créer une porte CX à longue portée aux deux extrémités d'une ligne unidimensionnelle (1D). Les étapes comprennent les éléments suivants :
- Initialiser le qubit de contrôle dans
- Préparer les paires de Bell
- Mesurer les paires de qubits voisins
- Appliquer les corrections par feedforward dépendantes des MCM
def lrcx(distance, prep_barrier=True, pre_measure_barrier=True):
qc = initialize_circuit(distance)
qc = prepare_bell_pairs(qc, prep_barrier)
qc = measure_bell_basis(qc, pre_measure_barrier)
qc = apply_ffwd_corrections(qc)
return qc
qc = lrcx(distance)
# Apply the measurement in the XX, YY, and ZZ bases
qc_XX, qc_YY, qc_ZZ = [
measure_in_basis(qc, basis=basis) for basis in ["XX", "YY", "ZZ"]
]
qc_YY.draw(
output="mpl", fold=-1, scale=0.5
) # Circuit for measuring in the YY basis
Implémentation unitaire avec permutation des qubits vers le milieu
Pour comparaison, nous examinons d'abord le cas où une porte CNOT à longue portée est implémentée en utilisant des connexions entre plus proches voisins et des portes unitaires. Dans la figure suivante, à gauche se trouve un circuit pour une porte CNOT à longue portée sur une chaîne 1D de n qubits soumise uniquement à des connexions entre plus proches voisins. Au milieu se trouve une décomposition unitaire équivalente implémentable avec des portes CNOT locales, de profondeur de circuit .
Le circuit au milieu peut être implémenté comme suit :
def cnot_unitary(distance):
"""Generate a long range CNOT gate using local CNOTs on a 1D
chain of qubits subject to n
nearest-neighbor connections only.
Args:
distance (int) : The distance of the CNOT gate,
with the convention that
a distance of 0 is a nearest-neighbor CNOT.
Returns:
QuantumCircuit: A Quantum Circuit implementing a
long-range CNOT gate
between qubit 0 and qubit distance+1
"""
assert distance >= 0
n = distance # number of qubits between target and control
qr = QuantumRegister(
n + 2, name="q"
) # Circuit with n qubits between control and target
cr = ClassicalRegister(
2, name="cr"
) # Classical register for measuring control and target qubits
qc = QuantumCircuit(qr, cr, name="CNOT_unitary")
control_qubit = 0
qc.h(control_qubit) # Prepare the control qubit in the |+> state
k = int(n / 2)
qc.barrier()
for i in range(control_qubit, control_qubit + k):
qc.cx(i, i + 1)
qc.cx(i + 1, i)
qc.cx(-i - 1, -i - 2)
qc.cx(-i - 2, -i - 1)
if n % 2 == 1:
qc.cx(k + 2, k + 1)
qc.cx(k + 1, k + 2)
qc.barrier()
qc.cx(k, k + 1)
for i in range(control_qubit, control_qubit + k):
qc.cx(k - i, k - 1 - i)
qc.cx(k - 1 - i, k - i)
qc.cx(k + i + 1, k + i + 2)
qc.cx(k + i + 2, k + i + 1)
if n % 2 == 1:
qc.cx(-2, -1)
qc.cx(-1, -2)
return qc
qc_uni = cnot_unitary(distance)
Nous construisons maintenant les circuits qui mesurent dans les bases , et , de la même manière que pour les circuits dynamiques ci-dessus.
# Apply the measurement in the XX, YY, and ZZ bases
qc_uni_XX, qc_uni_YY, qc_uni_ZZ = [
measure_in_basis(qc_uni, basis=basis) for basis in ["XX", "YY", "ZZ"]
]
qc_uni_YY.draw(
output="mpl", fold=-1, scale=0.5
) # Circuit for measuring in the YY basis

Maintenant que nous avons construit à la fois les circuits dynamiques et les circuits unitaires pour un exemple à petite échelle avec distance=6, nous les transpilons pour les exécuter d'abord sur un simulateur sans bruit.
from qiskit_aer import AerSimulator
aer_backend = AerSimulator()
pm_sim = generate_preset_pass_manager(
optimization_level=0, backend=aer_backend
)
# Dynamic circuits
isa_sim_dyn = pm_sim.run([qc_XX, qc_YY, qc_ZZ])
# Unitary circuits
isa_sim_uni = pm_sim.run([qc_uni_XX, qc_uni_YY, qc_uni_ZZ])
Étape 3 : Exécuter à l'aide des primitives Qiskit
Nous pouvons maintenant exécuter l'expérience sur le backend simulateur sans bruit. Nous utilisons le Sampler de Qiskit Runtime avec AerSimulator comme mode de backend pour exécuter les circuits.
sampler_sim = Sampler(mode=aer_backend)
sim_job = sampler_sim.run(isa_sim_dyn + isa_sim_uni)
sim_results = sim_job.result()
Étape 4 : Post-traiter et renvoyer le résultat dans le format classique souhaité
Après l'exécution réussie des expériences, nous procédons maintenant au post-traitement des comptages de mesures pour en extraire des métriques significatives. Dans cette étape, nous :
- Définissons des métriques de qualité pour évaluer les performances du CX à longue portée.
- Calculons les valeurs moyennes des opérateurs de Pauli à partir des résultats de mesure bruts.
- Les utilisons pour calculer la fidélité de l'état de Bell généré.
Dans une simulation sans bruit, nous allons vérifier que la métrique de fidélité est pour les circuits construits. Dans les expériences sur les QPU réels, cette analyse fournira une image claire de la performance des circuits dynamiques par rapport à l'implémentation unitaire de référence.
Métriques de qualité
Pour évaluer le succès du protocole CX à longue portée, nous mesurons à quel point l'état de sortie est proche de l'état de Bell idéal. Un moyen pratique de quantifier cela est de calculer la fidélité de l'état en utilisant les valeurs moyennes des opérateurs de Pauli. Nous pouvons calculer la fidélité pour un état de Bell sur l'état de contrôle et cible après avoir déterminé , et . En particulier,
Pour calculer ces valeurs moyennes à partir des données de mesure brutes, nous définissons un ensemble de fonctions utilitaires :
compute_ZZ_expectation: À partir des comptages de mesures, calcule la valeur moyenne d'un opérateur de Pauli à deux qubits dans la base .compute_fidelity: Combine les valeurs moyennes de , et dans l'expression de fidélité ci-dessus.get_counts_from_bitarray: Utilitaire pour extraire les comptages à partir des objets de résultats du backend.
def compute_ZZ_expectation(counts):
total = sum(counts.values())
expectation = 0
for bitstring, count in counts.items():
# Ensure bitstring is 2 bits
z1 = (-1) ** (int(bitstring[-1]))
z2 = (-1) ** (int(bitstring[-2]))
expectation += z1 * z2 * count
return expectation / total
def compute_fidelity(counts_xx, counts_yy, counts_zz):
xx, yy, zz = [
compute_ZZ_expectation(c) for c in [counts_xx, counts_yy, counts_zz]
]
return 1 / 4 * (1 + xx - yy + zz)
# Dynamic fidelity
counts_xx = sim_results[0].data.cr.get_counts()
counts_yy = sim_results[1].data.cr.get_counts()
counts_zz = sim_results[2].data.cr.get_counts()
fidelity_dyn = compute_fidelity(counts_xx, counts_yy, counts_zz)
# Unitary fidelity
counts_xx = sim_results[3].data.cr.get_counts()
counts_yy = sim_results[4].data.cr.get_counts()
counts_zz = sim_results[5].data.cr.get_counts()
fidelity_uni = compute_fidelity(counts_xx, counts_yy, counts_zz)
print(f"Dynamic fidelity (distance={distance}): {fidelity_dyn:.4f}")
print(f"Unitary fidelity (distance={distance}): {fidelity_uni:.4f}")
Dynamic fidelity (distance=6): 1.0000
Unitary fidelity (distance=6): 1.0000
Comme attendu dans une simulation sans bruit, les fidélités des circuits dynamiques et unitaires sont .
Exemple à grande échelle sur matériel réel
Nous rassemblons maintenant tous ces détails en un seul flux de travail à plus grande échelle, qui est ensuite exécuté sur du matériel quantique réel.
Générer des circuits pour différentes distances
Nous générons maintenant des circuits CX à longue portée pour une gamme de séparations entre qubits allant jusqu'à 60 qubits d'écart. Pour chaque distance, nous construisons des circuits qui mesurent dans les bases , et , qui seront utilisés ultérieurement pour calculer les fidélités.
La liste des distances comprend des séparations à courte et longue portée, avec distance = 0 correspondant à un CX entre plus proches voisins. Ces mêmes distances seront également utilisées pour générer ultérieurement les circuits unitaires correspondants à des fins de comparaison.
# -------------------------Step 1-------------------------
distances = [
0,
1,
2,
3,
6,
11,
16,
21,
28,
35,
44,
55,
60,
] # Distances for long range CX. distance of 0 is a nearest-neighbor CX
distances.sort()
assert min(distances) >= 0
basis_list = ["XX", "YY", "ZZ"]
# Dynamic circuits
circuits_dyn = []
for distance in distances:
for basis in basis_list:
circuits_dyn.append(
measure_in_basis(lrcx(distance, prep_barrier=False), basis=basis)
)
print(f"Number of circuits: {len(circuits_dyn)}")
# Unitary circuits
circuits_uni = []
for distance in distances:
for basis in basis_list:
circuits_uni.append(
measure_in_basis(cnot_unitary(distance), basis=basis)
)
print(f"Number of circuits: {len(circuits_uni)}")
Maintenant que nous avons à la fois des circuits dynamiques et unitaires pour une gamme de distances, nous sommes prêts pour la transpilation. Nous devons d'abord sélectionner un dispositif backend.
# -------------------------Step 2-------------------------
# Set up access to IBM Quantum devices
from qiskit.circuit import IfElseOp
service = QiskitRuntimeService()
backend = service.least_busy(
operational=True, simulator=False, min_num_qubits=156
)
L'étape suivante garantit que le backend prend en charge l'instruction if_else, qui est requise pour la nouvelle version des circuits dynamiques. Comme cette fonctionnalité est encore en accès anticipé, nous ajoutons explicitement IfElseOp à la cible du backend si elle n'est pas déjà disponible.
if "if_else" not in backend.target.operation_names:
backend.target.add_instruction(IfElseOp, name="if_else")
Utiliser la chaîne de fidélité de couche pour sélectionner une chaîne 1D
Puisque nous voulons comparer les performances des circuits dynamiques et unitaires sur une chaîne 1D, nous utilisons la chaîne de fidélité de couche pour sélectionner une topologie linéaire de la meilleure chaîne de qubits du dispositif. Cela garantit que les deux types de circuits sont transpilés sous les mêmes contraintes de connectivité, permettant une comparaison équitable de leurs performances.
# This selects best qubits for longest distance and uses
# the same control for all lengths
lf_qubits = backend.properties().to_dict()[
"general_qlists"
] # best linear chain qubits
chosen_layouts = {
distance: [
val["qubits"]
for val in lf_qubits
if val["name"] == f"lf_{distances[-1] + 2}"
][0][: distance + 2]
for distance in distances
}
print(chosen_layouts[max(distances)]) # best qubits at each distance
[11, 12, 13, 14, 15, 19, 35, 34, 33, 39, 53, 54, 55, 59, 75, 74, 73, 72, 71, 70, 69, 68, 67, 66, 65, 64, 63, 62, 61, 76, 81, 82, 83, 84, 85, 86, 87, 97, 107, 108, 109, 110, 111, 98, 91, 92, 93, 94, 95, 99, 115, 114, 113, 119, 133, 132, 131, 138, 151, 150, 149, 148]
isa_circuits_dyn = []
isa_circuits_uni = []
# Using the same initial layouts for both circuits for better
# apples to apples comparison
for qc in circuits_dyn:
pm = generate_preset_pass_manager(
optimization_level=1,
backend=backend,
initial_layout=chosen_layouts[qc.num_qubits - 2],
)
isa_circuits_dyn.append(pm.run(qc))
for qc in circuits_uni:
pm = generate_preset_pass_manager(
optimization_level=1,
backend=backend,
initial_layout=chosen_layouts[qc.num_qubits - 2],
)
isa_circuits_uni.append(pm.run(qc))
print(
f"2Q depth: "
f"{isa_circuits_dyn[14].depth(lambda x: x.operation.num_qubits == 2)}"
)
isa_circuits_dyn[14].draw("mpl", fold=-1, idle_wires=0)
2Q depth: 2
print(
f"2Q depth: "
f"{isa_circuits_uni[14].depth(lambda x: x.operation.num_qubits == 2)}"
)
isa_circuits_uni[14].draw("mpl", fold=-1, idle_wires=False)
2Q depth: 13

Visualiser les qubits utilisés pour le circuit LRCX
Dans cette section, nous examinons comment le circuit LRCX est mappé sur le matériel. Nous commençons par visualiser les qubits physiques utilisés dans le circuit, puis étudions comment la distance contrôle-cible dans le placement impacte le nombre d'opérations.
# Note: the qubit coordinates must be hard-coded.
# The backend API does not currently provide this information directly.
# If using a different backend, you will need to
# adjust the coordinates accordingly,
# or set the qubit_coordinates = None to use the default layout coordinates.
def _heron_coords_r2():
"""Generate coordinates for the Heron layout in R2. Note"""
cord_map = np.array(
[
[
0,
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
3,
7,
11,
15,
0,
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
1,
5,
9,
13,
0,
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
3,
7,
11,
15,
0,
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
1,
5,
9,
13,
0,
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
3,
7,
11,
15,
0,
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
1,
5,
9,
13,
0,
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
3,
7,
11,
15,
0,
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
],
-1
* np.array([j for i in range(15) for j in [i] * [16, 4][i % 2]]),
],
dtype=int,
)
hcords = []
ycords = cord_map[0]
xcords = cord_map[1]
for i in range(156):
hcords.append([xcords[i] + 1, np.abs(ycords[i]) + 1])
return hcords
# Visualize the active qubits in the circuit layout
plot_circuit_layout(
circuit=isa_circuits_uni[-1],
backend=backend,
view="physical",
qubit_coordinates=_heron_coords_r2(),
)
Ensuite, nous exécutons l'expérience sur le backend réel. Nous utilisons également le traitement par lots pour exécuter efficacement l'expérience sur plusieurs essais. L'exécution d'essais répétés nous permet de calculer des moyennes pour une comparaison plus précise entre les méthodes unitaire et dynamique, ainsi que de quantifier leur variabilité en comparant les écarts entre les exécutions.
# -------------------------Step 3-------------------------
num_trials = 10
jobs_uni = []
jobs_dyn = []
with Batch(backend=backend) as batch:
sampler = Sampler(mode=batch)
sampler.options.environment.job_tags = ["TUT_LRE"]
for _ in range(num_trials):
jobs_uni.append(sampler.run(isa_circuits_uni, shots=1024))
jobs_dyn.append(sampler.run(isa_circuits_dyn, shots=1024))
Nous calculons la fidélité pour les circuits CX à longue portée dynamiques. Pour chaque distance, nous extrayons les résultats de mesure dans les bases , et . Ces résultats sont combinés à l'aide des fonctions utilitaires définies précédemment pour calculer la fidélité selon . Cela fournit la fidélité observée du protocole exécuté dynamiquement à chaque distance.
# -------------------------Step 4-------------------------
fidelities_dyn = []
# loop over trials
for job in jobs_dyn:
result_dyn = job.result()
trial_fidelities = []
# loop over all distances
for ind, dist in enumerate(distances):
counts_xx = result_dyn[ind * 3].data.cr.get_counts()
counts_yy = result_dyn[ind * 3 + 1].data.cr.get_counts()
counts_zz = result_dyn[ind * 3 + 2].data.cr.get_counts()
trial_fidelities.append(
compute_fidelity(counts_xx, counts_yy, counts_zz)
)
fidelities_dyn.append(trial_fidelities)
# average over trials for each distance
avg_fidelities_dyn = np.mean(fidelities_dyn, axis=0)
std_fidelities_dyn = np.std(fidelities_dyn, axis=0)
Nous calculons maintenant la fidélité pour les circuits CX à longue portée unitaires, de la même manière que pour les circuits dynamiques ci-dessus.
fidelities_uni = []
# loop over trials
for job in jobs_uni:
result_uni = job.result()
trial_fidelities = []
# loop over all distances
for ind, dist in enumerate(distances):
counts_xx = result_uni[ind * 3].data.cr.get_counts()
counts_yy = result_uni[ind * 3 + 1].data.cr.get_counts()
counts_zz = result_uni[ind * 3 + 2].data.cr.get_counts()
trial_fidelities.append(
compute_fidelity(counts_xx, counts_yy, counts_zz)
)
fidelities_uni.append(trial_fidelities)
# average over trials for each distance
avg_fidelities_uni = np.mean(fidelities_uni, axis=0)
std_fidelities_uni = np.std(fidelities_uni, axis=0)
Tracer les résultats
Pour apprécier visuellement les résultats, la cellule ci-dessous trace les fidélités de porte estimées mesurées à différentes distances entre les qubits intriqués pour chaque méthode.
fig, ax = plt.subplots()
# Unitary with error bars
ax.errorbar(
distances,
avg_fidelities_uni,
yerr=std_fidelities_uni,
fmt="o-.",
color="c",
ecolor="c",
elinewidth=1,
capsize=4,
label="Unitary",
)
# Dynamic with error bars
ax.errorbar(
distances,
avg_fidelities_dyn,
yerr=std_fidelities_dyn,
fmt="o-.",
color="m",
ecolor="m",
elinewidth=1,
capsize=4,
label="Dynamic",
)
# Random gate baseline
ax.axhline(y=1 / 4, linestyle="--", color="gray", label="Random gate")
legend = ax.legend(frameon=True)
for text in legend.get_texts():
text.set_color("black")
legend.get_frame().set_facecolor("white")
legend.get_frame().set_edgecolor("black")
ax.set_title(
"Bell State Fidelity vs Control–Target Separation", color="black"
)
ax.set_xlabel("Distance", color="black")
ax.set_ylabel("Bell state fidelity", color="black")
ax.grid(linestyle=":", linewidth=0.6, alpha=0.4, color="gray")
ax.set_ylim((0.2, 1))
ax.set_facecolor("white")
fig.patch.set_facecolor("white")
for spine in ax.spines.values():
spine.set_visible(True)
spine.set_color("black")
ax.tick_params(axis="x", colors="black")
ax.tick_params(axis="y", colors="black")
plt.show()
D'après le graphique de fidélité ci-dessus, le LRCX n'a pas systématiquement surpassé l'implémentation unitaire directe. En fait, pour les courtes séparations contrôle-cible, le circuit unitaire a atteint une fidélité plus élevée. Cependant, pour les séparations plus grandes, le circuit dynamique commence à atteindre une meilleure fidélité que l'implémentation unitaire. Ce comportement n'est pas inattendu sur le matériel actuel : bien que les circuits dynamiques réduisent la profondeur du circuit en évitant les longues chaînes de SWAP, ils introduisent un temps de circuit supplémentaire dû aux mesures en milieu de circuit, au feedforward classique et aux délais de chemin de contrôle. La latence ajoutée augmente la décohérence et les erreurs de lecture, ce qui peut l'emporter sur les économies de profondeur pour les courtes distances.
Néanmoins, nous observons un point de croisement où l'approche dynamique surpasse l'approche unitaire. C'est un résultat direct des différentes lois d'échelle : la profondeur du circuit unitaire croît linéairement avec la distance entre les qubits, tandis que la profondeur du circuit dynamique reste constante.
Points clés :
- Avantage immédiat des circuits dynamiques : La principale motivation actuelle est la réduction de la profondeur à deux qubits, pas nécessairement l'amélioration de la fidélité.
- Pourquoi la fidélité peut être moins bonne aujourd'hui : L'augmentation du temps de circuit due aux opérations de mesure et classiques domine souvent, en particulier lorsque la séparation contrôle-cible est petite.
- Perspectives : À mesure que le matériel s'améliore, notamment avec une lecture plus rapide, une latence de contrôle classique plus courte et une réduction de la surcharge liée aux opérations en milieu de circuit, nous devrions nous attendre à ce que ces réductions de profondeur et de durée se traduisent par des gains de fidélité mesurables.
# Compute metrics for each distance, skipping the basis circuits since
# they are identical for each distance
depths_2q_dyn = [
c.depth(lambda x: x.operation.num_qubits == 2)
for c in isa_circuits_dyn[::3]
]
meas_dyn = [
sum(1 for instr in c.data if instr.operation.name == "measure")
for c in isa_circuits_dyn[::3]
]
depths_2q_uni = [
c.depth(lambda x: x.operation.num_qubits == 2)
for c in isa_circuits_uni[::3]
]
meas_uni = [
sum(1 for instr in c.data if instr.operation.name == "measure")
for c in isa_circuits_uni[::3]
]
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
axes[0].plot(
distances, depths_2q_uni, "o-.", color="c", label="Unitary (2Q depth)"
)
axes[0].plot(
distances, depths_2q_dyn, "o-.", color="m", label="Dynamic (2Q depth)"
)
axes[0].set_xlabel("Number of qubits between control and target")
axes[0].set_ylabel("Two-qubit depth")
axes[0].grid(True, linestyle=":", linewidth=0.6, alpha=0.4)
axes[0].legend()
axes[1].plot(
distances, meas_uni, "o-.", color="c", label="Unitary (# measurements)"
)
axes[1].plot(
distances, meas_dyn, "o-.", color="m", label="Dynamic (# measurements)"
)
axes[1].set_xlabel("Number of qubits between control and target")
axes[1].set_ylabel("Number of measurements")
axes[1].grid(True, linestyle=":", linewidth=0.6, alpha=0.4)
axes[1].legend()
fig.suptitle("Scaling of Unitary vs Dynamic LRCX with Distance", fontsize=12)
plt.tight_layout()
plt.show()
Ce graphique de profondeur à deux qubits met en évidence l'avantage principal du LRCX implémenté avec des circuits dynamiques : les performances restent essentiellement constantes à mesure que la séparation entre les qubits de contrôle et cible augmente. En revanche, l'implémentation unitaire croît linéairement avec la distance en raison des chaînes de SWAP nécessaires. La profondeur capture la mise à l'échelle logique des opérations à deux qubits, tandis que le nombre de mesures reflète la surcharge supplémentaire des circuits dynamiques. Ces mesures sont efficaces, car elles sont effectuées en parallèle, mais elles introduisent tout de même un coût fixe sur le matériel actuel.
Pourquoi la fidélité peut être moins bonne aujourd'hui : L'augmentation du temps de circuit due aux opérations de mesure et classiques domine souvent, en particulier lorsque la séparation contrôle-cible est petite. Par exemple, la durée moyenne de lecture sur un processeur Heron r2 est de 2 280 ns, alors que la durée de sa porte à 2Q n'est que de 68 ns.
À mesure que les latences de mesure et classiques s'améliorent, nous nous attendons à ce que la mise à l'échelle à profondeur constante et à nombre de mesures constant des circuits dynamiques produise des avantages clairs en termes de fidélité et de temps d'exécution sur des circuits plus grands.
Prochaines étapes
Si tu as trouvé ce travail intéressant, tu pourrais être intéressé(e) par les ressources suivantes :
Références
[1] Efficient Long-Range Entanglement using Dynamic circuits, by Elisa Bäumer, Vinay Tripathi, Derek S. Wang, Patrick Rall, Edward H. Chen, Swarnadeep Majumder, Alireza Seif, Zlatko K. Minev. IBM Quantum, (2023). https://arxiv.org/abs/2308.13065